
My HuggingFace JAX Community Week Experience
Published:
On June 23, the HuggingFace team announced that they are planning to host a community week together with the people from the Google Cloud team. The main gist of this event was getting everyone to learn and use HuggingFace’s newly integrated JAX framework. But aside from just learning from tutorials, we were equipped with blazing fast TPUs thanks to the amazing Google Cloud team 🤯.
Hearing this, I naturally gravitated to registering for the event, and so I immediately invited my good friend, Steven Limcorn, to join me in this event as it was a group work. We hopped into a Discord call and the brainstorm begins..
📝 Plan on Paper
Right off the bat, we were thinking: Indonesian Language Model. Why? Because it is the model which we both had experience training and it would be fun to learn JAX in the process (since we usually work in PyTorch).
At the same time, we came into a dilemma. If you know a thing or two about Indonesian NLP, there are two major players in masked language modeling (MLM): IndoNLU’s IndoBERT and IndoLEM’s IndoBERT.
We thought, okay, how can we make something different? Or perhaps something better? Rambling through Indonesian datasets, the first thing that came to mind is, of course, the OSCAR dataset (16GB). But, we thought, if we wanted the model to perform better than the existing models, we should be using a larger dataset, shouldn’t we?

Despite the dilemma, we ended up posting the project proposal on the HuggingFace forums anyway. Luckily, a day later, we got a reply from a user that suggested two alternative datasets: CC100 (36GB) and mC4 (230GB). So we thought, cool, let’s train the best Indonesian model!
⚙ Setting up
To kick things off, we began by setting up the TPU Virtual Machine as instructed by the HuggingFace team. We found no major issues and the installation went pretty smoothly. All tokenizing and training scripts were ready, so no major code modification was needed to get the project started.
Fast forward, we began with training a tokenizer. “So, which dataset will we use?”, I asked. OSCAR? CC100? mC4? Heck, if we want to train the best model, why not use the largest dataset? And so I trained a ByteLevelBPETokenizer on the Indonesian mC4 subset, which took a good hour or two.. Fast forward, the tokenization finished and we’re ready to train! Or are we…?
Being naive, I naturally ran the training script and boy was I wrong. It took ages for the gigantic mC4 dataset just to pre-process; I was impatient. “Since we’re only creating a “trial” RoBERTa Base model, why bother training it on a huge dataset?” I thought.
And so we took the step back and trained on OSCAR instead. Being 93% smaller in size, it took only a couple of minutes to train a tokenizer. Likewise, the pre-processing step only took a while before the model actually began training.
🚶♂️ Roaming to Thai NLP
It was at this point that I left my computer to get a haircut (true story). While the model kept training and my hair was being cut, I paused and thought: “why not participate in another project?” since others were participating in >1 project at the same time.
Returning to my computer after the haircut (and shower) ended, I browsed through existing project proposals and found a less crowded one: Thai RoBERTa project. Cool! Why not join another project that similarly works on a low-resource language? Perhaps I can learn a thing or two from it…
And so I contacted the participant who’s responsible for the project: Sakares Saengkew. We talked, exchanged ideas, and ultimately agreed to work on this project together. What I didn’t expect was becoming really good friends with someone whom I have never met in person, let alone be based in Thailand 😆.
The more we talked, the more our friendship bonded. Along the lines of conversation, we found out that we both enjoyed watching Dota 2, so that became the topic of our conversation for a good while 😂. Games aside, Sakares’ original plan kept going, though with some hurdles along the way.
🤔 Debugging
As for my Indonesian model, it kept training and training, with an estimated training time of about 18 hours. At first, we were so happy that training actually took off. Mind you, we were Linux and machine learning amateurs, so getting things off the ground was already satisfying!
Both the training and evaluation loss seems to be decreasing well, with the accuracy attaining decent results in the first few epochs “all is well”, we thought.
With some more hours to kill, I decided to train another language model still using HuggingFace’s JAX framework, but this time on a personal Google Colab notebook. It was trained on the very low-resource language of Sundanese and the training and evaluation loss decreased just fine. It also achieved a decent accuracy, but something odd came to my realization…
Despite the accuracy reports, the language model was spitting out jibberish, unreflective of the results. “Maybe something is wrong?”, I thought. Indeed, I had trouble converting the JAX model to PyTorch, due to the usage of FP16. “Aha!”, that’s where I thought the problem lies.
And so I opened a Github Issue on the matter, to which HuggingFace’s Patrick von Platen responded quickly and professionally. Apparently, a “reverse-trick” which I attempted to do to convert FP16 JAX models to FP32 was indeed the fix my model needed. What about the model’s results, though? It remained jibberish, sadly.
At this point, I thought I did something wrong along the training pipeline. “Whatever”, I said to myself, let’s just focus on the main dish: the Indonesian model.
✌ Not One, But Two
Seeing my Indonesian model training just fine, I wanted to test its intermediate results after training it for about 6-8 hours. Pulled the model weights from the HuggingFace Hub, and voila, jibberish output! The beast which I expected to have trained is no different from its Sundanese counterpart 😓.

Now I’m left with two problems instead of one. Badly trained models, but why? Naturally, I investigated the common ground between these two models: JAX and OSCAR dataset. The former seemed innocent though, since nobody has reported a problem with it, and I’m sure the HuggingFace team has checked the framework thoroughly…
“It must be the dataset!”, I thought. But wait, while I dug through issues in HuggingFace’s Github repo, I found someone who’s facing a similar problem as I am: Birger Moëll. Like Birger, our models were spitting jibberish despite a decent training result. Eliminating the possible causes, we suspect that it is the dataset who’s the culprit of it all, or is it?
We had a short interaction within the Github Issue which Birger raised, but it translated to an even longer conversation back in the official Slack channel. We exchanged dataset cleaning ideas and discussed our plans for this event. What we didn’t realize is that we’re becoming good friends from this exchange.
💀/💸 Failure and Fortune
The event lasted for two weeks and there are countless lessons I learned along the way from the people of HuggingFace, the people I met along the way, and of course, training the model itself. We all had a happy ending with our model training at the end of the day, but it wasn’t smooth like many of us expected, or at least I did.
For instance, the Indonesian RoBERTa Base model turned out to be just fine. I pushed the final version after the entire training finished, converted the model to PyTorch, and somehow it wasn’t outputting jibberish?! All along, I could have possibly pulled the first epoch of the model, or maybe even epoch zero judging from the performance 🤦♂️.
I was so close to giving up, but seeing the Base model working just as intended, I was back on track and became motivated to work on this project once again. The next boss to conquer: RoBERTa Large.
I naively thought training the Large rendition would be as trivial as training the Base model. But it turned out to be even more frustrating than the first attempt… Why? Well, unlike the Base model, the RoBERTa Large didn’t like the same value of learning rate. The training loss fluctuated constantly, leading me to think that it is overshooting due to a learning rate that’s too high (I was using 2e-4).
And thus I decided to decrease it by about an order of magnitude (2e-5). It was, unsurprisingly, too low of a learning rate.. Even from the first few epochs, I can see that the model is not learning. Killed the process and increased the learning rate to 7e-5. At that point, it was about midnight, so I crossed my fingers and went to sleep. I woke up excited the next day, and just like that, it still didn’t learn 😤. Not a lucky number 7 after all…
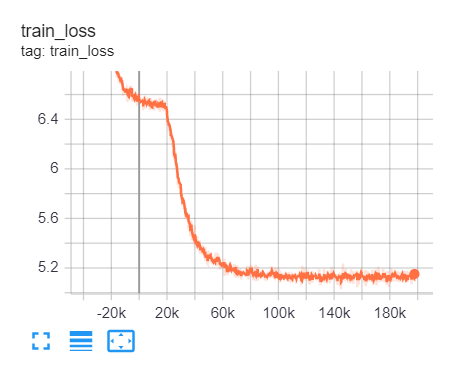
Seeing how my time was running out (the model took ~2.5 days to train), I increased the learning rate just slightly this time (8e-5). Crossed my fingers yet again and left the model to train…
As it resumed training, I was delighted to hear that my friends were finding the light at the end of their tunnels as well. Birger’s models began to return more sensible outputs, and we found out that Sakares’ slightly incorrect tokenization scheme was the culprit of the slow model training.
As for myself, I was honestly disappointed to see the Large model still suffering from the same issue of “not learning” as the evaluation loss looked somewhat flat at first. But talking to my teammate Steven, he suggested that we leave it as is this time and see how it will fare, since we’re really out of time at this point.
To my surprise, it finally learned! After about three/four epochs (~20 hours), the evaluation loss began to decrease! I can finally sleep without having anxiety about model training, for the least. We quickly realized that with the epochs we set, it was impossible for it to zip to a very high accuracy as we wanted. But either way, it served as a lesson of learning-rate tuning and taught us that a scheduler’s warmup steps are equally as important.
😮 Extension == Hope
Sometime later, the HuggingFace team announced that they will be extending the TPU access (and hence the event) for several more days than the initial deadline. For me, this meant more exploring and maximizing the tools at hand.
I decided to hop on the Thai NLP train and train a very trivial Thai GPT-2 on the OSCAR dataset. Since I had only about a day at most, I could only train for very little epochs and left the model as I slept the night. To my surprise, it actually trained well?! The evaluation loss decreased as expected, and the predictions are relatively decent for the short window of time!
I immediately notified and told Sakares to play around with the model as I barely understood Thai. And indeed, the model’s predictions were reflective of the training metrics reported.
What’s unfortunate is that our original plan of training a Thai RoBERTa was too late for the deadline. Regardless, Sakares said that it’s okay since it could still be trained using Colab Pro, if we wanted to.
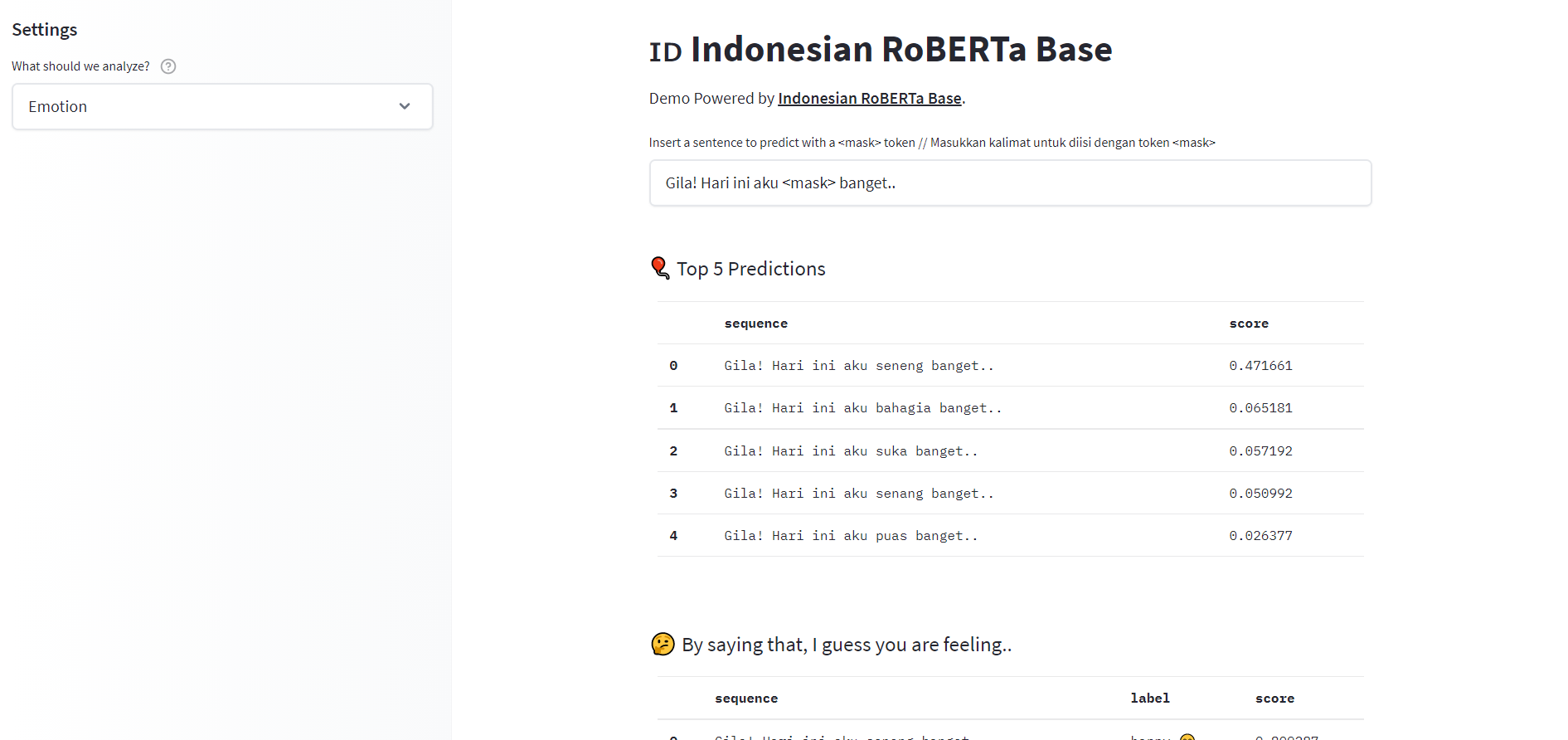
As the HuggingFace team announced their beta feature Spaces, my team and I began ideating for a demo of our trained models. We fine-tuned the Indonesian RoBERTa base models to existing downstream tasks from IndoNLU, including emotion classifier, sentiment analysis, and part-of-speech (POS) tagging. We used the first two in our model demo, as well as the pre-trained masked language model itself.
As for my Thai NLP project with Sakares, we ended up scavenging the last-minute Thai GPT-2 for model demo 😂. Birger similarly deployed various models into one awesome demo titled Language Explorer. In the end, we really found the light at the end of our tunnels.
🚀 Closing Thoughts
Although none of us managed to secure the top-15 projects, the virtual event was nonetheless a memorable one. I learned a ton from the people I met, and ultimately had fun participating in my first-ever online community event hosted by HuggingFace and Google Cloud. I cannot thank my friends and organizers enough for making this experience possible. And I cannot wait to join the next HuggingFace community event 🤗.
To Steven, Sakares, Birger, and the friendliest team behind HuggingFace & JAX, thank you.
