
Handwritten Javanese Script Classification
Published:
Aksara Jawa, or the Javanese Script is the core of writing the Javanese language and has influenced various other regional languages such as Sundanese, Madurese, etc. The script is now rarely used on a daily basis, but is sometimes taught in local schools in certain provinces of Indonesia.
Specific Form of Aksara
The Javanese Script which we will be classifiying is specifically Aksara Wyanjana’s Nglegena, or its basic characters. The list consists of 20 basic characters, without their respective Pasangan characters.
Dataset
Since I have not been able to find a handwritten Javanese Script dataset on the internet, I have decided to contact one of my English highschool teachers who has once showed my class her ability to write Javanese Script. The characters were written on paper, scanned, and edited manually. Credits to Mm. Martha Indrati for the help!
Image Classification
This project is very much inspired from datasets like MNIST and QMNIST which are handwritten digits and is a go-to dataset for starting to learn image classification. The end goal of this project is to be able to create a deep learning model which will be able to classify handwritten Javanese Script to a certain degree of accuracy.
Code
The main framework to be used is fastai-v2, which sits on top of PyTorch. Fastai-v2 is still under development as of the time of this writing, but is ready to be used for basic image classification tasks.
from fastai2.vision.all import *
import torch
Load Data
The data has been grouped per class folder, which we’ll load up and later split into training (70%) and validation (30%) images.
path = Path("handwritten-javanese-script-dataset")
Notice we’re using a small batch size of 5, mainly because we only have 200 images in total.
Here we’ll apply cropping and resizing as transformations to our image since most of the characters do not fully occupy the image size. Additionally, we’ll resize to 128px.
dblock = DataBlock(blocks = (ImageBlock(cls=PILImageBW), CategoryBlock),
get_items = get_image_files,
splitter = GrandparentSplitter(valid_name='val'),
get_y = parent_label,
item_tfms = [CropPad(90), Resize(128, method=ResizeMethod.Crop)])
dls = dblock.dataloaders(path, bs=5, num_workers=0)
dls.show_batch()

There are only 20 types of characters in the type of Aksara which we’ll be classifying.
dls.vocab
(#20) ['ba','ca','da','dha','ga','ha','ja','ka','la','ma'...]
Model
We’ll be using XResNet50 as the model, which is based on the Bag of Tricks paper and is an “extension” to the ResNet50 architecture. We’ll pass our data, tell which metrics we’d like to observe, utilize LabelSmoothingCrossEntropy, and add MixUp as our callback.
learn = Learner(dls, xresnet50(c_in=1, n_out=dls.c), metrics=accuracy, loss_func=LabelSmoothingCrossEntropy(), cbs=MixUp)
Training Model
With all things in place, let’s finally train the model to learn from the given dataset and predict which class the image belongs to.
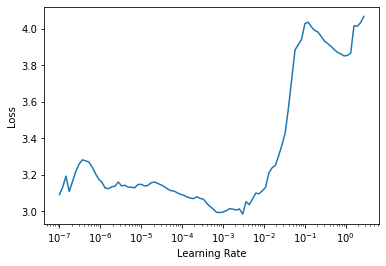
learn.lr_find()
SuggestedLRs(lr_min=0.0003019951749593019, lr_steep=6.309573450380412e-07)
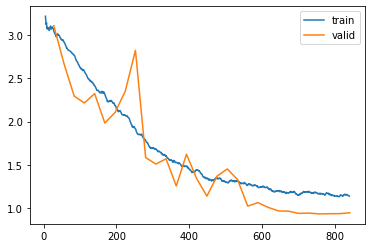
learn.fit_one_cycle(30, 3e-4, cbs=SaveModelCallback(monitor='accuracy', fname='best_model'), wd=0.4)
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 3.067268 | 3.108827 | 0.050000 | 00:04 |
| 1 | 2.929908 | 2.669373 | 0.333333 | 00:04 |
| 2 | 2.769148 | 2.293764 | 0.383333 | 00:04 |
| 3 | 2.588481 | 2.215439 | 0.316667 | 00:04 |
| 4 | 2.416248 | 2.324036 | 0.283333 | 00:04 |
| 5 | 2.324458 | 1.983255 | 0.533333 | 00:04 |
| 6 | 2.189000 | 2.105889 | 0.383333 | 00:04 |
| 7 | 2.078479 | 2.350886 | 0.333333 | 00:04 |
| 8 | 1.922369 | 2.823610 | 0.216667 | 00:05 |
| 9 | 1.790820 | 1.584189 | 0.650000 | 00:05 |
| 10 | 1.683853 | 1.509675 | 0.583333 | 00:04 |
| 11 | 1.598790 | 1.570487 | 0.650000 | 00:04 |
| 12 | 1.528586 | 1.256149 | 0.833333 | 00:04 |
| 13 | 1.484508 | 1.623523 | 0.566667 | 00:04 |
| 14 | 1.437240 | 1.340925 | 0.750000 | 00:04 |
| 15 | 1.345987 | 1.138785 | 0.816667 | 00:05 |
| 16 | 1.350891 | 1.370259 | 0.716667 | 00:04 |
| 17 | 1.297572 | 1.453033 | 0.666667 | 00:04 |
| 18 | 1.318248 | 1.330522 | 0.750000 | 00:04 |
| 19 | 1.263931 | 1.023822 | 0.900000 | 00:04 |
| 20 | 1.247242 | 1.063768 | 0.900000 | 00:04 |
| 21 | 1.234829 | 1.009032 | 0.933333 | 00:05 |
| 22 | 1.203268 | 0.968369 | 0.950000 | 00:04 |
| 23 | 1.178766 | 0.965601 | 0.916667 | 00:04 |
| 24 | 1.156069 | 0.939599 | 0.933333 | 00:04 |
| 25 | 1.183693 | 0.943586 | 0.933333 | 00:04 |
| 26 | 1.166053 | 0.933629 | 0.933333 | 00:04 |
| 27 | 1.162939 | 0.936014 | 0.933333 | 00:04 |
| 28 | 1.132883 | 0.936722 | 0.933333 | 00:04 |
| 29 | 1.138776 | 0.946842 | 0.933333 | 00:04 |
Better model found at epoch 0 with accuracy value: 0.05000000074505806.
Better model found at epoch 1 with accuracy value: 0.3333333432674408.
Better model found at epoch 2 with accuracy value: 0.38333332538604736.
Better model found at epoch 5 with accuracy value: 0.5333333611488342.
Better model found at epoch 9 with accuracy value: 0.6499999761581421.
Better model found at epoch 12 with accuracy value: 0.8333333134651184.
Better model found at epoch 19 with accuracy value: 0.8999999761581421.
Better model found at epoch 21 with accuracy value: 0.9333333373069763.
Better model found at epoch 22 with accuracy value: 0.949999988079071.
learn.recorder.plot_loss()
learn.save('stage-1')
Analyze Results
After training, let’s see how well our model learned. Any incorrect prediction in a random batch will have its label colored red.
learn.show_results()

Instead of only viewing a batch, let’s analyze the results from the entire validation dataset.
interp = ClassificationInterpretation.from_learner(learn)
This confusion matrix lists all the actual versus predicted labels. The darker the blue on the diagonal line, the better our model is at predicting.
interp.plot_confusion_matrix(figsize=(8,8), dpi=60)

On the other hand, this type of interpretation shows several of the predicted images, what our model thinks it is, and how confident it is with that prediction.
interp.plot_top_losses(9, figsize=(10,9))

Predicting External Images
To see how our model’s regularization fairs, let’s attempt to feed it an external data and see what it predicted.
from PIL import Image
def open_image_bw_resize(source) -> PILImageBW:
return PILImageBW(Image.open(source).resize((128,128)).convert('L'))
The following character is supposed to be ma and was picked randomly from available images on the internet.
test0 = open_image_bw_resize('test-image-0.jpg')
test0.show()
<matplotlib.axes._subplots.AxesSubplot at 0x1e8960ffaf0>

Feed it through the model and see its output.
learn.predict(test0)[0]
'ma'
Luckily, the model was able to predict the character correctly. To challenge the model even more, I tried to write Javanese Script characters myself and see what the model predicts. Do note that I do not have any background in writing Javanese Scripts, so pardon my skills.
The following character is supposed to be ca.
test1 = open_image_bw_resize('test-image-1.jpg')
test1.show()
<matplotlib.axes._subplots.AxesSubplot at 0x1e895ef6610>

learn.predict(test1)[0]
'ca'
This character is supposed to be wa.
test2 = open_image_bw_resize('test-image-2.jpg')
test2.show()
<matplotlib.axes._subplots.AxesSubplot at 0x1e8c2a21580>

learn.predict(test2)[0]
'ca'
Well that’s an incorrect guess, which is reasonable firstly because of my poor handwriting skills, and secondly the model was trained on a person’s particular style of handwriting - which in this case is my teacher’s. There could be many other factors which caused the incorrect guess, such as overfitting by the model, small dataset and possibly more.
Closing Remarks
There are several possible improvements which could be made, one of which is to increase the variety and the size of the dataset, since the model is only training on a single person’s handwriting. It’ll be better in terms of regularization to add other people’s handwriting into the mix as well.
That’s it for this mini project of mine. Thanks for your time and I hope you’ve learned something!
